// RU version: multimodal-rag.ru.md
// USER GUIDE
// TL;DR
Drop a file into Google Drive. Ask a question in natural language. Get an answer grounded in your own documents -- with clickable source links to the original text file, image, PDF, audio clip, or video.
Visitor access is read-only. Ingestion happens off-site on the owner's Drive. Anyone visiting can query the existing corpus (see What's in scope) but cannot add documents.
// WHAT IS RAG
Retrieval-Augmented Generation. The LLM does not answer from its training memory -- it answers from documents retrieved on demand from a vector database. Multimodal means the same system ingests text, images, PDFs, audio, and video into one shared vector space, so a text question can surface a video frame or a PDF page as a source.
// HOW TO USE
- Click the empty input field -- a suggested query autofills. Press EXEC (or Enter) to send it, or erase it and type your own question.
- Watch the typing indicator -- the response arrives as a full block once ready.
- Sources appear under each answer. Media tiles open the original file in Google Drive in a new tab.
- CLR wipes the current conversation -- messages from the screen, sessionStorage, and the current in-flight request (if any).
About chat history. Your conversation is kept only inside this browser tab. Refresh preserves it. What clears it: CLR, or closing the tab. Separate tabs do not share history -- each new one starts empty.
// WHAT'S IN SCOPE
The knowledge base is a fixed 13-file corpus. Questions outside this scope are declined, not hallucinated.
| Type | Files | Topics |
|---|
| Text (.txt) | 7 | cybersecurity, Agile, API design, cloud architecture, Linux CLI, networking, cryptography |
| Image (.png) | 2 | cryptography diagrams |
| Audio (.mp3) | 1 | DevOps practices (~75s) |
| Video (.mp4) | 2 | keyboard typing, UI animation |
| PDF (.pdf) | 1 | SQL Joins guide -- 6 join types (INNER, LEFT, RIGHT, FULL, CROSS, SELF) |
Ingest accepts every format supported by Gemini Embedding 2: image -- PNG, JPEG; audio -- MP3, WAV; video -- MP4, MOV (H264, H265, AV1, VP9 codecs). Size and duration caps live in Limits & Timeouts.
// TECHNICAL REFERENCE
// STACK
| Layer | Technology | Role |
|---|
| Trigger | Google Drive Trigger | Watches folder for new files |
| File storage | Google Drive | Source of documents |
| Captioning | Gemini 2.0 Flash | Structured captions for all media types (image, audio, video, PDF) |
| Embedding | Gemini Embedding 2 | Natively multimodal embeddings |
| Vector DB | Pinecone | Store and query embeddings |
| Reranker | Pinecone bge-reranker-v2-m3 | cross-encoder (joint-scoring model that reads question+candidate together — markedly more accurate than cosine) second-pass ordering |
| Query classifier | google/gemini-2.0-flash-001 via OpenRouter | Intent + modality + standalone query |
| Chat LLM | anthropic/claude-sonnet-4 via OpenRouter | Generate grounded answers from retrieved context |
| Orchestration | n8n (self-hosted) | 3 workflows -- ingestion, chat, error handler |
| Frontend | Astro 6 + vanilla TypeScript | Static page, per-tab chat state |
// ARCHITECTURE
Three n8n workflows cooperate. ingestion (24 nodes) watches Google Drive and feeds Pinecone. chat (9 nodes) answers user questions. error_handler (2 nodes) catches unhandled failures in either of the other two.
// INGESTION -- runs on every new file in the watched Drive folder.
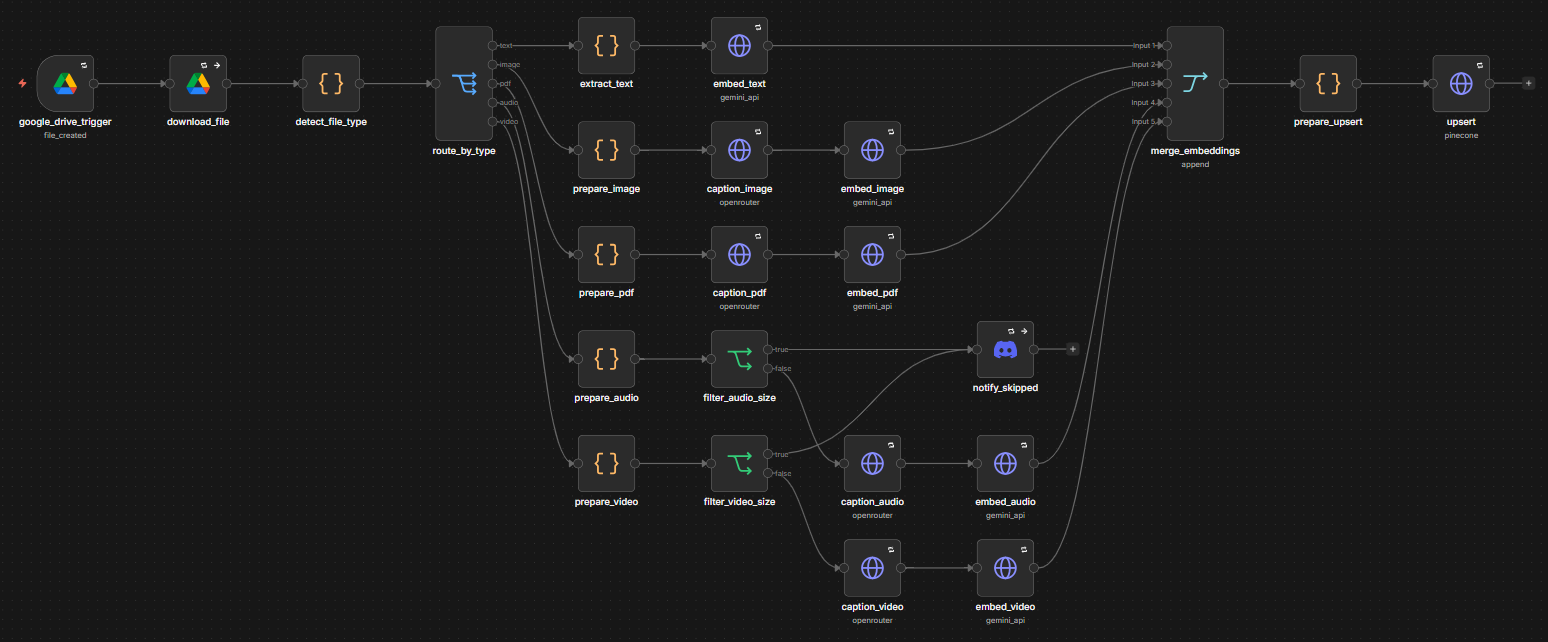
google_drive_trigger -- polls the watched Drive folder for new filesdownload_file -- downloads the binary into the workflowdetect_file_type -- reads MIME and extension, labels the file with a fileCategoryroute_by_type -- switch, fans out to one of five modality branchesextract_text / prepare_image / prepare_pdf / prepare_audio / prepare_video -- per-modality prep (text -- sentence-aware chunking; image/pdf -- base64 encoding; audio/video -- base64 + duration probe with cap enforcement)filter_audio_size / filter_video_size -- IF nodes that split each branch: oversized items route to notify_skipped, valid items continue to captionnotify_skipped -- Discord alert when a file is rejected by a cap (audio > 180s, video > 120s); independent of error_handler -- this is a graceful skip, not an unhandled errorcaption_image / caption_pdf / caption_audio / caption_video -- Gemini 2.0 Flash produces a structured JSON caption (text branch skips this)embed_text / embed_image / embed_pdf / embed_audio / embed_video -- Gemini Embedding 2 (text-only for the text branch; multipart binary+caption fusion for media)merge_embeddings -- 5-way merge of per-branch outputsprepare_upsert -- assembles the Pinecone vectors payload with metadata; filters out items flagged _oversized by the size routers so skipped files never reach the vector storeupsert -- writes vectors to Pinecone
// CHAT -- invoked per user question.

chat_webhook -- entrypoint, accepts POST with the question and optional historyrewrite_question -- Gemini 2.0 Flash classifies intent + modality and emits a standalone retrieval queryembed_question -- turns the rewritten query into a vectorquery -- Pinecone retrieval, top candidates by cosine similarity; for pure_meta queries a fileType metadata filter is applied pre-retrieval so top-K contains only files of the requested modalityrerank -- Pinecone bge-reranker-v2-m3 reorders candidates with a cross-encoderbuild_context -- filters by score, applies modality boost for content queries, assembles prompt contextllm_answer -- Claude Sonnet 4 generates the grounded answerformat_response -- shapes payload for the frontend (answer, media, sources)respond_webhook -- returns JSON to the client
// ERROR HANDLER -- receives failed executions from both ingestion and chat.
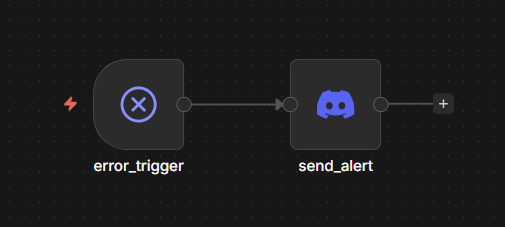
error_trigger -- fires when ingestion or chat raises an unhandled error (both are linked via n8n's errorWorkflow setting)send_alert -- posts a Discord message: workflow name, error type (NodeApiError, NodeOperationError, etc.), error message, UTC timestamp, and a link to the specific execution
// KEY PATTERNS
Architecture above describes what each node does. This section is about why it was built this way -- design decisions that are not obvious from the node list.
- Enriched multipart embeddings for all media. A raw PNG, WAV, or MP4 binary does not carry its topic in a form a text query can match --
diagram of public-key crypto cannot retrieve a picture that has no text metadata. So every media file is captioned by Gemini 2.0 Flash into structured JSON (type, title, key_topics, terminology[], content, questions[]) tailored per modality, and the caption text is sent together with the raw binary as two parts in a single Gemini Embedding 2 call. The model fuses both into one vector -- so a text query matches against both the raw media and its description at once. Captions are also stored in metadata and fed to the LLM as context. - Two-stage retrieval: vector query + cross-encoder rerank. Pure cosine similarity is fast but imprecise -- it reliably returns candidates in the right topic area but often ranks them wrong within it. So stage 1 casts a wider net from Pinecone, and stage 2 passes those candidates through the
bge-reranker-v2-m3 cross-encoder, which reads each (question, candidate) pair together and scores them jointly -- much more accurate than cosine alone. If every reranked item falls below the floor, top-1 is still passed to the LLM -- empty context would force the LLM into either a blind refusal or a fall-back to parametric knowledge. Preserving top-1 leaves the next pattern (Three-tier policy below) something to act on for either a partial answer or an honest refusal. - Three-tier answering policy. Without explicit policy, LLMs either hallucinate when context is thin or refuse too easily when partial information is available -- two different failures. The Claude system prompt enforces three tiers: Tier 1 (direct) -- answer fully from context; Tier 2 (partial) -- answer from what is retrieved and note the scope in one sentence; Tier 3 (empty) -- respond exactly
That information is not available in the knowledge base.. Effect: the user gets useful partial answers instead of blanket refusals, and gets an honest refusal instead of a fabrication when the topic truly is not covered. - Fallback thresholds when rerank is unavailable. If the rerank API is down, we would have no second-pass quality filter and the LLM would see either noise or nothing. So
build_context falls back to raw vector scores with per-modality thresholds (text stricter, short media more lenient -- short captions score lower in cosine terms by nature). Top-1 is kept even if nothing clears the threshold, so the user still gets a grounded answer while rerank is recovering. - LLM-driven intent + modality classification. Not every user input is a substantive question.
hi, ?, and "how many videos do you have?" each need different handling, and "what about the second one?" means nothing without context. Regex heuristics also do not scale across EN / RU / UA. So rewrite_question (Gemini 2.0 Flash, temperature 0) does three things in one call: classify the input as greeting | pure_meta | content, detect whether a specific modality is asked about, and rewrite pronouns against recent history into a self-contained retrieval query. Greetings still pass through embed / query / rerank, but build_context discards the results and returns empty sources so the UI shows no source tiles for "hi"; pure_meta queries route through the pre-retrieval filter below; content queries keep cross-modal matches. - Pre-retrieval metadata filter for
pure_meta queries. Meta-questions about the corpus itself ("do you have any videos", "what PDFs are there", "how many audios") are structural -- they ask what exists, not what is content-relevant. Vector similarity and cross-encoder rerank are built to score content, not enumerate files; asked "how many videos", the reranker scores short video captions against an abstract count question and reliably demotes them below unrelated long text passages. So when the classifier tags the input as pure_meta with a specific modality, the Pinecone query attaches a metadata filter (fileType = modality) pre-retrieval. Top-K arrives already narrowed to the requested type, rerank sorts inside that clean pool, and the answer is correct regardless of how the cross-encoder feels about caption length. This is the self-query retrieval pattern: the LLM classifier derives a filter predicate (a filter condition like fileType = video), and the vector DB applies it structurally -- before the vector search. - Modality boost — survival mechanism for short captions. A reranker trained on text-heavy corpora tends to score short captions (an image, a short audio clip, a one-page PDF) lower than long text passages -- even when the short one is what the user actually wants. The boost loop in
build_context rescues items of the requested modality back into the result set, regardless of how the cross-encoder ranked them. It serves both intents but for different reasons. For content queries that mention a modality alongside a topic ("show me the image of AES"), the boost ensures cross-modal matches survive low rerank scores. For pure_meta queries, the boost is even more critical: pre-retrieval already narrows top-K to one modality, but the reranker routinely scores all of them under the floor when the question is abstract ("do you have any videos?") -- without the boost, a video listing query would return zero items. A strict-modality filter at the end (pure_meta-only) keeps the final list type-pure even after the boost runs. - Two-tier score floor: LLM context vs UI media tiles. A source that's marginally relevant can still help the LLM as background, but rendered as a media tile in the UI it looks like clutter or a wrong answer. So the rerank floor splits by purpose: items below 0.001 are dropped entirely (true noise); items between 0.001 and 0.5 are passed to the LLM as context but not rendered as tiles; items at 0.5 or above appear both as text context and as media tiles. The 0.5 floor is the industry-standard reranker relevance threshold (Pinecone, NVIDIA). Exception: when the user's query explicitly mentions a media type (modality hint from the classifier), at least one tile of that type should reach the UI even if the reranker scored it low — short captions are systematically underscored, but a user asking for a specific modality should see the answer rendered as a tile, not just described in text. Two cases:
pure_meta queries pass all matching items (Pinecone pre-filter already restricted retrieval to that fileType); content queries with a modality hint pass only the top-scoring item of that type (other items must still clear the floor, so a stray noise match on the same type doesn't appear). - Multi-turn coherence. A chatbot that forgets between messages cannot handle "what about the second one?", and one that remembers but contradicts itself loses user trust. The frontend sends recent turns back on each request as
history; the query rewriter uses it to resolve pronouns, and the answer generator embeds history as a <history> block before <documents> with an explicit instruction to stay consistent with prior answers and acknowledge new information rather than silently overriding. <history> is treated as untrusted data -- the prompt forbids following any instructions found inside those tags, so a malicious earlier turn cannot inject commands. - Filename-anchored embeddings. Two files with visually similar content can still mean different things --
symmetric-encryption.png and asymmetric-encryption.png could produce near-identical captions if both show an algorithm diagram. The filename carries signal the content alone does not, so the filename is woven into the embedding text itself: title: <fileName> | text: <content or caption>. This is the recommended v2 pattern -- a top-level title parameter is not supported in Gemini Embedding 2; asymmetric-retrieval instructions live inside the prompt. Effect: a query about "symmetric encryption" lands on the symmetric file, not the asymmetric one, even when the content looks similar to the embedder. - Unified vector space with asymmetric task-prefix. User questions tend to be short (
AES-256?); documents tend to be long explanations (AES-256 is a symmetric block cipher...). If both sides were embedded the same way, they would land in different regions of vector space and retrieval would miss obvious matches. Gemini Embedding 2 has no task_type parameter -- the role is encoded directly in the prompt: documents are embedded as title: <fileName> | text: <content>, queries as task: search result | query: <question>. Same model, same dimensions -- but each side carries its task instruction inside the text itself, so query and document embeddings land in the same region of space. - Sentence-aware chunking with overlap. Naive fixed-size chunking cuts text mid-sentence and splits key terms across chunk boundaries -- a query for
AES-256 could miss a chunk that only contains ...AES- or 256 is a.... Text files are instead split at sentence boundaries, with a 50-token overlap between consecutive chunks. Sentences stay whole, and concepts that span two sentences stay findable because both chunks carry the bridging phrase. - Pre-send duration probe with skip routing. Without validation, oversized files fail downstream when Gemini Embedding 2 rejects them for exceeding its 180s audio / 120s video caps -- a generic
NodeApiError in error_handler, with no signal the cause was duration. Duration is now probed before send: prepare_audio reads WAV via RIFF chunks and MP3 via ID3v2 skip + frame-header bitrate (CBR-approximation, ~5% off on VBR); prepare_video uses Drive's videoMediaMetadata.durationMillis as primary, with MP4/MOV mvhd → trak.mdia.mdhd binary parse as fallback for non-Drive sources. Oversized items get _oversized: true and bypass base64-encoding. filter_audio_size / filter_video_size IF nodes split each branch: oversized routes to notify_skipped (Discord alert: workflow name, file, scenario, probed duration vs cap, UTC timestamp, Drive link); valid continues to caption. Same-batch valid files are unaffected -- skip is per-item, not workflow-killing. prepare_upsert filters _oversized items before zipping, so Pinecone receives only valid embeddings. - Source-grounded, language-aware answers. Naive RAG setups answer in the language of the source documents, or mix languages, or drift away from the sources -- three different failure modes. A Ukrainian user asking about an English document still wants a Ukrainian answer that faithfully represents the English content. The system prompt has two explicit rules: ground every statement in retrieved documents (never draw from training-memory knowledge), and answer in the language of the question regardless of the source language.
Numeric parameters (top-K, rerank floor, timeouts, chunk size, caps) -- see Limits & Timeouts.
// LIMITS & TIMEOUTS
| Fetch timeout | 30s -- accommodates cold Gemini + Claude paths |
| Text chunking | ~400 tokens per chunk, 50-token overlap, sentence-aware |
| Embedding multipart parts | Gemini Embedding 2 per-call caps: ≤6 images, ≤1 PDF file (which itself can be up to 6 pages), ≤1 audio, ≤1 video per embedContent call; ≤8192 input tokens overall. Workflow currently sends 2 entries in content.parts: 1 binary + 1 caption text. See Possible Improvements |
| Audio length | 180s -- enforced by prepare_audio (WAV via RIFF, MP3 via frame-header bitrate); oversized files routed to notify_skipped |
| Video length | 120s -- enforced by prepare_video (Drive videoMediaMetadata primary, MP4/MOV mvhd / mdhd binary parse fallback); oversized files routed to notify_skipped |
| Conversation history | last 10 turns (20 messages) per tab; all sent to Claude on each request |
| Assistant answer clamp | 500 chars per assistant message before being written to history -- keeps the per-request payload and the LLM history-block token cost compact (10 turns × 500 chars ≈ 1250 tokens, vs. unbounded). Trade-off: a follow-up that references a detail past char 500 of an earlier long answer won't see it (rare in practice) |
| Vector retrieval | top-K = 20 cosine-nearest from Pinecone -- wide enough for rerank's second pass to find the right answer, narrow enough to keep cross-encoder latency reasonable (latency grows linearly with K) |
| Rerank | After the cross-encoder rerank: top-N = 5 passed to the LLM (enough context for the main topic plus adjacent details without prompt bloat); two-tier score floor -- 0.001 for LLM context (drops true noise) and 0.5 for media tiles in the UI (industry-standard reranker threshold); modality boost cap 6 -- ceiling on the final source set after the boost runs. Boost can append items of the requested fileType on top of rerank's top-5, but stops once the total reaches 6 -- prevents runaway growth while still guaranteeing the requested modality is represented |
| Embedding dimensions | 1536 |
| Classifier timeout | 20s, 2 attempts with 3s backoff |
| HTTP retry (other nodes) | 2-3 attempts per node, 2-3s backoff |
// ERRORS
Server-side. Both chat and ingestion workflows are linked to the error_handler workflow via n8n's errorWorkflow setting -- any unhandled error in either pipeline fires a Discord alert: workflow name, error type, message, UTC timestamp, and a link to the specific execution. On top of that, the chat pipeline sets onError: continueRegularOutput on HTTP nodes, so transient API failures surface to the user as a friendly error message rather than a hung request. All HTTP nodes retry on failure with backoff (count and wait -- see Limits & Timeouts).
Frontend states.
The [ CONN: <state> ] indicator at the bottom of the chat input bar reflects whether the backend was reachable on the last request -- ESTABLISHED means the backend answered (even with a 4xx -- the connection is fine, the request was just rejected), LOST means the request couldn't get through (timeout / network failure / 5xx), MISSING means there's no webhook URL configured at build time. The table below maps each scenario to its CONN state and the on-screen message.
| Cause | CONN state | User sees |
|---|
| User pressed CLR mid-request | -- | Messages wipe; no error rendered |
| Request timeout exceeded (>30s) | LOST | Request timed out. The service is slow or unreachable. |
| Network error / fetch failure | LOST | Connection error. Check your network. |
| HTTP 5xx | LOST | Service unavailable. Try again later. |
| HTTP 4xx (config-side) | ESTABLISHED | Request rejected by server. The service may be misconfigured. |
| Webhook URL absent at build | MISSING | No error bubble -- only [ CONN: MISSING ] in the indicator; EXEC disabled |
// POSSIBLE IMPROVEMENTS
Capabilities within reach but not currently implemented -- documented here so the gap between "what the API supports" and "what this workflow does today" is explicit.
- Per-chunk PDF embedding. Today the workflow sends an entire PDF as one
inlineData blob and stores one vector per file. Splitting long PDFs into 6-page chunks (Gemini Embedding 2's per-call PDF limit) and embedding each chunk separately would yield finer-grained retrieval -- page ranges become individually addressable in the index, and a query about a specific section lands on the right chunk instead of the whole document. - Folder-convention image batches. Gemini Embedding 2 can fuse up to 6 images into a single aggregated vector, useful when several images form one logical unit (a multi-step diagram, a screenshot sequence). The current Drive trigger fires per file. A convention like "files in a sub-folder share one vector" would unlock multi-image fusion without changing the trigger model.
// TEST DATA & EVALUATION
The system is tested against a 39-case end-to-end suite covering 14 failure-mode classes -- and verifying it doesn't fall on any of them. The 14 split into 6 project-specific (no analog in Barnett et al. 2024 Seven Failure Points of RAG): language drift, prompt injection, multi-turn coherence, modality disambiguation, typo tolerance, and corpus-meta queries (asking what exists in the corpus vs. what's written inside its files). The remaining 8 cover all 7 of Barnett's FPs N-to-1 (multiple of our classes can target the same FP -- different angles of the same failure mode): FP1 missing content -- hallucination guards & negative refusals; FP2 missed top-ranked + FP3 not-in-context -- cross-topic sources where retrieval/consolidation get confused; FP4 not extracted -- faithful extraction from context; FP5 wrong format -- implicitly via completeness tests like "list every SQL JOIN type"; FP6 incorrect specificity -- fragment & generic queries; FP7 incomplete -- answer completeness. Plus general edge-case robustness across all FPs.
Suite source: evaluation.json (the 39 cases), run_eval.py (Python runner), manual-tests.md (UI smoke list).